Simple Kubernetes Templating
Tamal Saha ([email protected])
08/02/2017
This document describes a simple package manager for Kubernetes. The general model is based on how tools like glide, dep or npm works.
Goals:
- Templating
- Package Management
- Dependency Management
- Release processing
- Release History
Name of tool:
I am going to refer to this as X.
Problems with Helm/Tiller:
It is designed for installing other people’s random stuff from some central repo. We want to use templating to manage our own stuff.
No authN/Z. https://github.com/kubernetes/helm/issues/1918
30K ft view:
You have some git repo. In this repo, you have a folder of templated YAML files. You also have a X.yaml file in the root of your repo. This is similar to glide.yaml in GO or package.json in npm. You define other other projects on which you depend on for YAMLs. Those projects will also need to have their own x.yaml at the root.
Vendoring Phase
Now, you can vendor your YAMLs.
$ x up (like glide up).
This will do dependency resolution and flattening like glide and put all your dependency YAMLs in a x-vendor/ folder. I like to call this “external dependency”.
I propose that there is no separate version for YAMLs. The git repo from where YAMLs are pulled is the version of the YAML. This is different from package.json where you can define a separate version. I want to avoid a central package manager for YAMLs (like that Helm is doing now). My reasons are:
These are just a bunch of YAML files. There are no real reason to have a registry (like Docker). No more chart registry, app registry, etc.
I don’t want a gatekeeper. Currently I have tried to publish stuff to Kubernetes/charts repo. We push releases but we have no idea when our pr for chart is accepted.
I also find it confusing that Chart version # is different from the project’s version number. Like we released Voyager 3.0.0 but Chart version is 1.0.0.
After “x up”‘is run there is a clear DAG of YAML file groups.
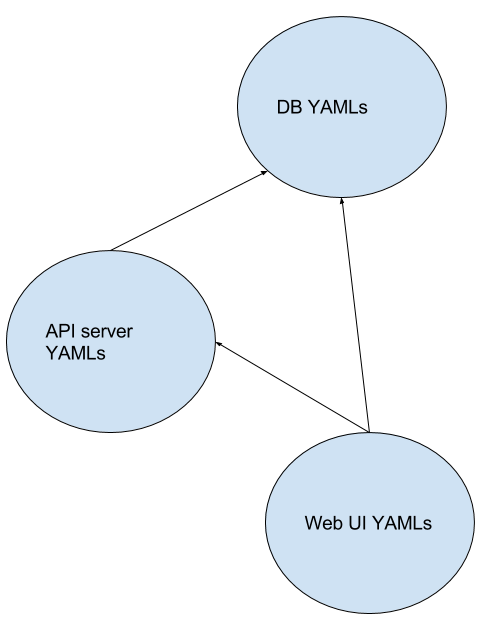
Rendering Phase
Now, I can add a values file for my repo and any dependencies I have. For rendering templates, there will be no ordering. This is analogous to the push strategy (section 7.1). I think the render function looks like this:
render ([]YAMLs, Values from source repo, Values from this repo, ENV vars, cli flags)
Here, the values file is overridden in this order:
- Values from source repo < Values from this repo < ENV vars < cli flags
*I am not sure you can just take values from source repo. **I think the vendoring process will guide from where a particular version of an ancestor is coming and take the dependency from there. *
There can be a separate values file for each ancestor dependencies. This is the 3rd parameter in the render() function above. This is useful. This way you can set your own defaults from any ancestor repo.
Each repo can provide multiple default values file for its own YAMLs. For example in Voyager, we have 5-6 different set of default values for each cloud provider. Currently doing something like this seems impossible in Helm. I call this “flavor”.
**Secrets are not realized at this point. **This allows anyone to commit generated YAMLs in their repos.
At this point every YAML can be identified by their name like: ns/deploy/nginx
pkg-1/ns/deploy/apiserver
These names are used by DSl in apply phase.
Apply Phase:
This is the phase where YAMLs are applied to cluster. The command may be “x apply”. There are 3 sub phases.
Secret Realization sub-phase: At this point, x goes into the cluster, searches a secret by name, merges them to produce the final secret YAML.
**Security Checks: **This can check for security vulnerability etc for images. Also, verify image policy stuff. https://kubernetes.io/docs/admin/admission-controllers/#imagepolicywebhook . This can be skipped in initial versions.
Actual apply:
This phase essentially replicates what a human operator will do to actually apply the YAMLs to a cluster. There might be number of approaches:
The simplest version will be just
kubectl apply. This will apply YAMLs in random order (I believe).Use the DAG from external dependency. But within a dependency, do
kubectl apply. Continue to be next vertex in DAG if the previous kubectl apply is successful.We can come up with some DSL to drive this process. One DSL can be array of array of strings.
[clusterrole, clusterrolebinding, ns/serviceaccount]
[pkg-1/ns/deployment, pkg-1/ns/service]
[pkg-2/ns/deployment, pkg-2/ns/service]
[ns/deployment, ns/service]
Note that, RBAC objects included in this repo are applied first. Then, YAMLs from ancestor pkg-1 are applied. Then YAMLs from ancestor pkg-2 are applied. Finally deployments and services from current repo are applied. The fact that cluster roles should be created before deployments in this repo, I call it “internal dependency”.
I think in general any repo should be able to tell how its YAMLs and its ancestors YAMLs will be applied in a recursive fashion. This essentially becomes a DAG.
One unknown is, how to trigger, go to next step. This can be also part of the DSL.
- [clusterrole.yaml, clusterrolebinding.yaml, serviceaccount.yaml]
|
| trigger if condition C is true
v
[pkg-1/deployment.yaml, pkg-1/service.yaml]
[pkg-2/deployment.yaml, pkg-2/service.yaml]
[deployment.yaml, service.yaml]
Now, condition C can be defined in many ways. One option can be some script code (JS may be ?). If there is no special trigger condition, it means, x can continue as long as the previous step was successful. Some example conditions might be, wait for StatefulSet # of replicas to be equal to desired # of replicas., etc.
Choice of Templating:
I think it will be easy to get started with YAML + GO template. But the process should be extensible to other types of templating like Jsonnet, Jinja, etc.
Q:
In this proposal, the real name (and its ID) is only known after rendering phase. This is similar to what Helm does. But for a project to define internal dependency, it needs a way to identify each object before rendering is done. How can this be done?
Q: What happens if it fails in the middle. I don’t know if automatic reversal will be possible. But that will be desired.
Q: How do you delete YAMLs:
- This needs history. What you did not last time? What are you doing this time? Then delete the ones that are not in new version.
Release History:
This can’t be in git, since this will have real YAMLs. I think it will similar to what Helm does today.
Background Reading
https://medium.com/@sdboyer/so-you-want-to-write-a-package-manager-4ae9c17d9527
https://github.com/sdboyer/gps/wiki/Introduction-to-gps
https://github.com/sdboyer/gps/blob/master/example.go
https://github.com/sdboyer/gps